Elasticsearch Aggregation - elasticsearch - elasticsearch tutorial - elastic search
Elasticsearch Aggregation
- The aggregations framework helps provide aggregated data based on a search query.
- It is based on simple building blocks called aggregations, that can be composed in order to build complex summaries of the data.
- An aggregation can be seen as a unit-of-work that builds analytic information over a set of documents.
- The context of the execution defines what this document set is (e.g. a top-level aggregation executes within the context of the executed query/filters of the search request).
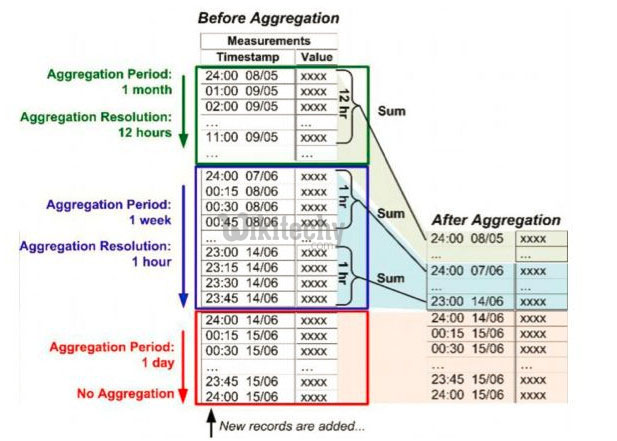
learn elasticsearch tutorials - aggregation Example
- There are many different types of aggregations, each with its own purpose and output. To better understand these types, it is often easier to break them into four main families:
Metrics Aggregations:
- These aggregations help in computing matrices from the field’s values of the aggregated documents and sometime some values can be generated from scripts.
- Numeric matrices are either single-valued like average aggregation or multi-valued like stats.

learn elasticsearch tutorials - search results aggregation Example
Avg Aggregation:
- This aggregation is used to get the average of any numeric field present in the aggregated documents. For example,
POST http://localhost:9200/schools/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
{
"took":44, "timed_out":false, "_shards":{"total":5, "successful":5, "failed":0},
"hits":{
"total":3, "max_score":1.0, "hits":[
{
"_index":"schools", "_type":"school", "_id":"2", "_score":1.0,
"_source":{
"name":"Saint Paul School", "description":"ICSE Affiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi",
"zip":"110075", "location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}
},
{
"_index":"schools", "_type":"school", "_id":"1", "_score":1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location":[31.8955385, 76.8380405], "fees":2200,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}
},
{
"_index":"schools", "_type":"school", "_id":"3", "_score":1.0,
"_source":{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road", "city":"Jaipur", "state":"RJ",
"zip":"176114", "location":[26.8535922, 75.7923988], "fees":2500,
"tags":["Well equipped labs"], "rating":"4.5"
}
}
]
}, "aggregations":{"avg_fees":{"value":3233.3333333333335}}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
- If the value is not present in one or more aggregated documents, it gets ignored by default. You can add a missing field in the aggregation for treating missing value as default.
{
"aggs":{
"avg_fees":{
"avg":{
"field":"fees"
"missing":0
}
}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Cardinality Aggregation:
- This aggregation gives the count of distinct values of a particular field. For example,
POST http://localhost:9200/schools*/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"name"}}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
{
"name":"Government School", "description":"State Board Afiliation",
"street":"Hinjewadi", "city":"Pune", "state":"MH", "zip":"411057",
"location":[18.599752, 73.6821995], "fees":500, "tags":["Great Sports"],
"rating":"4"
},
{
"_index":"schools_gov", "_type": "school", "_id":"1", "_score":1.0,
"_source":{
"name":"Model School", "description":"CBSE Affiliation", "street":"silk city",
"city":"Hyderabad", "state":"AP", "zip":"500030",
"location":[17.3903703, 78.4752129], "fees":700,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3"
}
}, "aggregations":{"disticnt_name_count":{"value":3}}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
- Note − The value of cardinality is 3 because there are three distinct values in name — Government, School and Model.
Extended Stats Aggregation:
- This aggregation generates all the statistics about a specific numerical field in aggregated documents. For example,
POST http://localhost:9200/schools/school/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
{
"aggregations":{
"fees_stats":{
"count":3, "min":2200.0, "max":5000.0,
"avg":3233.3333333333335, "sum":9700.0,
"sum_of_squares":3.609E7, "variance":1575555.555555556,
"std_deviation":1255.2113589175156,
"std_deviation_bounds":{
"upper":5743.756051168364, "lower":722.9106154983024
}
}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
elasticsearch - elasticsearch tutorial - elastic search - elasticsearch sort - elasticsearch list indexes - elasticsearch node
Max Aggregation:
- This aggregation finds the max value of a specific numeric field in aggregated documents. For example,
POST http://localhost:9200/schools*/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
{
aggregations":{"max_fees":{"value":5000.0}}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Min Aggregation:
- This aggregation finds the max value of a specific numeric field in aggregated documents. For example,
POST http://localhost:9200/schools*/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
"aggregations":{"min_fees":{"value":500.0}}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Sum Aggregation:
- This aggregation calculates the sum of a specific numeric field in aggregated documents. For example,
POST http://localhost:9200/schools*/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
"aggregations":{"total_fees":{"value":10900.0}}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
- There are some other metrics aggregations which are used in special cases like geo bounds aggregation and geo centroid aggregation for the purpose of geo location.
Bucket Aggregations:
- These aggregations contain many buckets for different types of aggregations having a criterion, which determines whether a document belongs to that bucket or not. The bucket aggregations have been described below −
Children Aggregation:
- This bucket aggregation makes a collection of documents, which are mapped to parent bucket. A type parameter is used to define the parent index. For example, we have a brand and its different models, and then the model type will have the following _parent field −
{
"model" : {
"_parent" : {
"type" : "brand"
}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
- There are many other special bucket aggregations, which are useful in many other cases, those are −
- Date Histogram Aggregation
- Date Range Aggregation
- Filter Aggregation
- Filters Aggregation
- Geo Distance Aggregation
- GeoHash grid Aggregation
- Global Aggregation
- Histogram Aggregation
- IPv4 Range Aggregation
- Missing Aggregation
- Nested Aggregation
- Range Aggregation
- Reverse nested Aggregation
- Sampler Aggregation
- Significant Terms Aggregation
- Terms Aggregation
Aggregation Metadata:
- You can add some data about the aggregation at the time of request by using meta tag and can get that in response. For example,
POST http://localhost:9200/school*/report/_search
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Request Body:
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees"
}
}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Response:
{
"aggregations":{"min_fees":{"meta":{"dsc":"Lowest Fees"}, "value":2180.0}}
}