How to build an NLP pipeline
Following steps to build an NLP pipeline
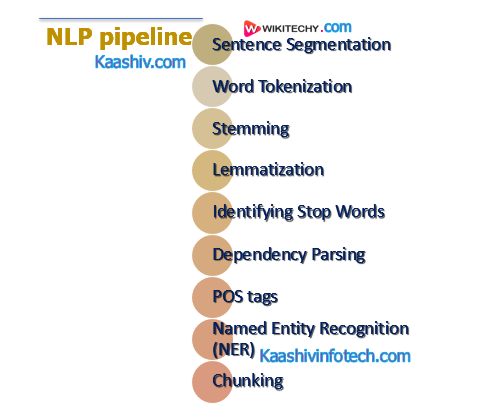
PipeLine
Step 1 : Sentence Segmentation
- Sentence Segment is the first step for building the NLP pipeline. It breaks paragraph into separate sentences.
- Example: Consider the following paragraph -
- “Kaashiv Infotech is one of the very best Inplant Training in India. This Company is runned by Microsofts Most valuable Proffessional”
- Sentence Segment produces the following result:
- “Kaashiv Infotech is one of the very best inplant training in India.”
- “This Company is runned by Microsofts Most valuable Proffessional”
Step 2 : Word Tokenization
- Word Tokenizer is used to break the sentence into separate words or tokens.
- Example:
- Kaashiv Infotech offers Corporate Training, Inplant Training, Online Training, and Season Training.
- Word Tokenizer generates the following result:
- “Kaashiv Infotech”, “offers”, “Corporate Training”, “Inplant Training”, “Online Training”, and “Season Training”.”,”.
Step 3 : Stemming
- Stemming is used to normalize words into its base form or root form.
- Eg, enjoys, enjoyed and enjoying, all these words are originated with a single root word "Enjoy." Big problem with stemming is that sometimes it produces the root word which may not have any meaning.
Step 4 : Lemmatization
- Lemmatization is quite similar to the Stemming. It is used to group different inflected forms of the word, called Lemma.
- Eg: In lemmatization, the words intelligence, intelligent, and intelligently has a root word intelligent, which has a meaning.
Step 5 : Identifying Stop Words
- In English, there are a lot of words that appear very frequently like "is", "and", "the", and "a". NLP pipelines will flag these words as stop words. Stop words might be filtered out before doing any statistical analysis.
- Example: She is a good Girl.
Step 6 : Dependency Parsing
- Dependency Parsing is used to find that how all the words in the sentence are related to each other.
Step 7 : POS Tags
- POS stands for parts of speech, which includes Noun, verb, adverb, and Adjective. It indicates that how a word functions with its meaning as well as grammatically within the sentences.
- Example: "Google" something on the Internet.
- Google is used as a verb, although it is a proper noun.
Step 8 : Named Entity Recognition (NER)
- Named Entity Recognition (NER) is the process of detecting the named entity such as person name, movie name, organization name, or location.
Step 9 : Chunking
- Chunking is used to collect the individual piece of information and grouping them into bigger pieces of sentences.